OpenClaw系列第24课:摄像头 / 音频 / 媒体节点实战
OpenClaw系列第24课:摄像头 / 音频 / 媒体节点实战
Kai这是「OpenClaw 教程课程」第 24 课。
前三课我们讲了多节点架构、Tailscale 组网和节点配对排错。今天把这些基础落到真实能力上:让 OpenClaw 看见、听见,并把媒体内容纳入工作流。
图:OpenClaw 的媒体节点能力可以把手机、Mac、摄像头、语音消息、图片附件和视频片段接入 Agent 工作流。
如果说第 21 课解决的是“设备怎么协作”,第 22 课解决的是“跨网络怎么连”,第 23 课解决的是“连不上怎么排查”,那第 24 课要解决的就是:
节点连上以后,怎么真正用起来?
这里最有代表性的能力就是:
- 摄像头拍照
- 摄像头短视频
- 屏幕录制
- 语音消息转文字
- 图片 / 音频 / 视频理解
- 媒体文件作为回复发送
- TTS 把文字变成语音
这些能力会让 OpenClaw 从“只会读文字的助手”,变成更接近真实世界的个人 AI 系统。
但也要先说清楚:
摄像头、麦克风、定位、屏幕录制都是高隐私能力,必须按最小权限开启。
这一课我们会边讲实战,边讲安全边界。
一、先建立一个媒体流向模型
在 OpenClaw 里,媒体相关能力大致有两条流向。
1)节点主动采集媒体
比如你让手机节点拍一张照片:
1 | Agent → Gateway → 手机 Node → camera.snap → 图片 → Gateway → Agent 分析 / 回复 |
或者让 macOS 节点录一段屏幕:
1 | Agent → Gateway → Mac Node → screen.record → mp4 → Gateway → Agent 分析 / 发送 |
2)用户发来媒体
比如你在 Telegram / WhatsApp 里发一张图片或一段语音:
1 | 用户发送媒体 → Gateway 下载附件 → media understanding → Agent 获得文字化上下文 → 回复用户 |
所以可以简单理解:
节点媒体能力负责“采集现实世界”,媒体理解负责“把媒体变成 Agent 能处理的上下文”。
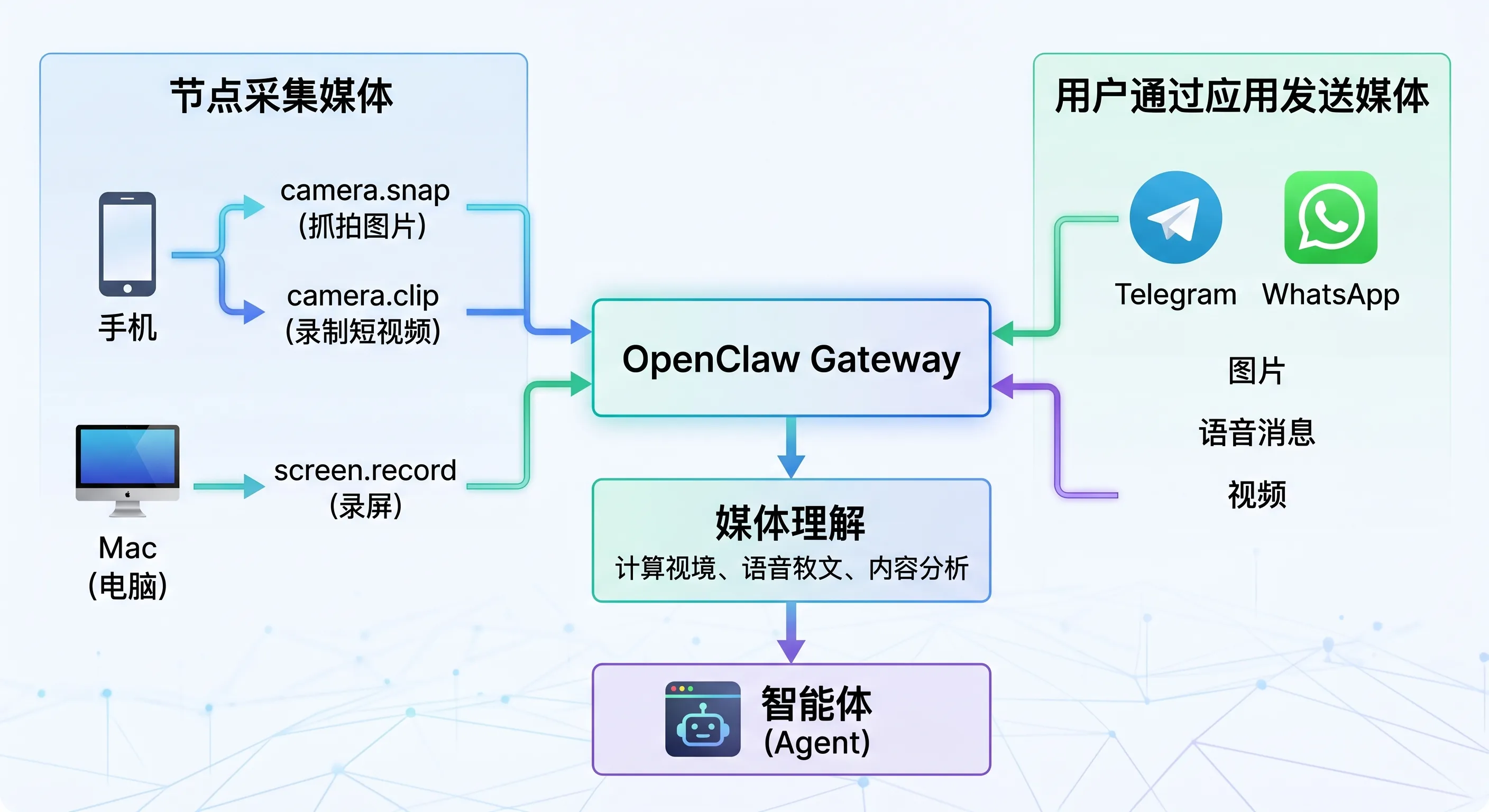
图:媒体可以从节点采集进入 Gateway,也可以从聊天渠道进入 Gateway,之后由 Agent 或 media understanding 处理。
二、本课会用到哪些能力?
这一课主要围绕五类能力:
1)Camera
用于拍照和录短视频。
常见命令:
1 | openclaw nodes camera list --node <id> |
2)Screen
用于屏幕录制,特别是 macOS 节点。
示例:
1 | openclaw nodes screen record --node <id> --duration 10s --fps 15 |
3)Media understanding
用于理解用户发来的图片、音频、视频。
比如:
- 图片描述
- 语音转文字
- 视频摘要
- 把语音转成
{{Transcript}}
4)Message media send
用于发送媒体回复。
示例:
1 | openclaw message send --media <path-or-url> --message "这是截图" |
5)TTS
用于把文字回复变成语音。
示例:
1 | /tts audio 你好,这是 OpenClaw 的语音回复。 |
这一课不会把每个 provider 的配置展开到很深。
重点是:你应该知道这些能力怎么串起来,以及什么时候该谨慎。
三、先检查节点是否适合做媒体节点
不要一上来就拍照。
先确认节点在线、已配对、有能力。
1 | openclaw nodes status |
重点看:
- node 是否 connected
- pairing role 是否包含 node
- commands 里有没有
camera.* - commands 里有没有
screen.* - permissions 里是否显示 camera / microphone / screen / location
- 平台是 iOS、Android、macOS 还是 headless node host
第 23 课讲过:
connected 不等于有目标能力。
所以每次调媒体能力前,先看 describe。
四、手机摄像头:最直接的现实世界输入
手机节点最适合做“随身感官”。
它可以帮 Agent 看:
- 房间状态
- 设备指示灯
- 包裹标签
- 白板内容
- 纸质文件
- 现场物品
- 路由器灯是否异常
查看摄像头列表
1 | openclaw nodes camera list --node <idOrNameOrIp> |
这个命令会列出节点上的 camera devices。
如果有多个摄像头,可以用 deviceId 指定。
拍照
1 | openclaw nodes camera snap --node <idOrNameOrIp> |
文档里说,CLI helper 会把返回的 base64 解码成临时文件,并打印:
1 | MEDIA:<path> |
也就是说,它不是只返回一串 base64,而是尽量给 Agent / 用户一个可用的媒体文件。
指定前后摄
1 | openclaw nodes camera snap --node <idOrNameOrIp> --facing front |
注意:
openclaw nodes camera snap默认可能会拍 front + back 两个方向,给 Agent 两个视角。
如果你只想拍一个方向,最好显式指定 --facing。
限制图片宽度
1 | openclaw nodes camera snap --node <idOrNameOrIp> --max-width 1280 |
为什么要限制?
因为图片太大:
- 传输慢
- base64 体积膨胀
- 可能超过模型 / 消息限制
- 没必要
文档里提到,照片会被 recompress,保证 base64 payload 不超过一定大小。
但你自己也应该主动控制尺寸。
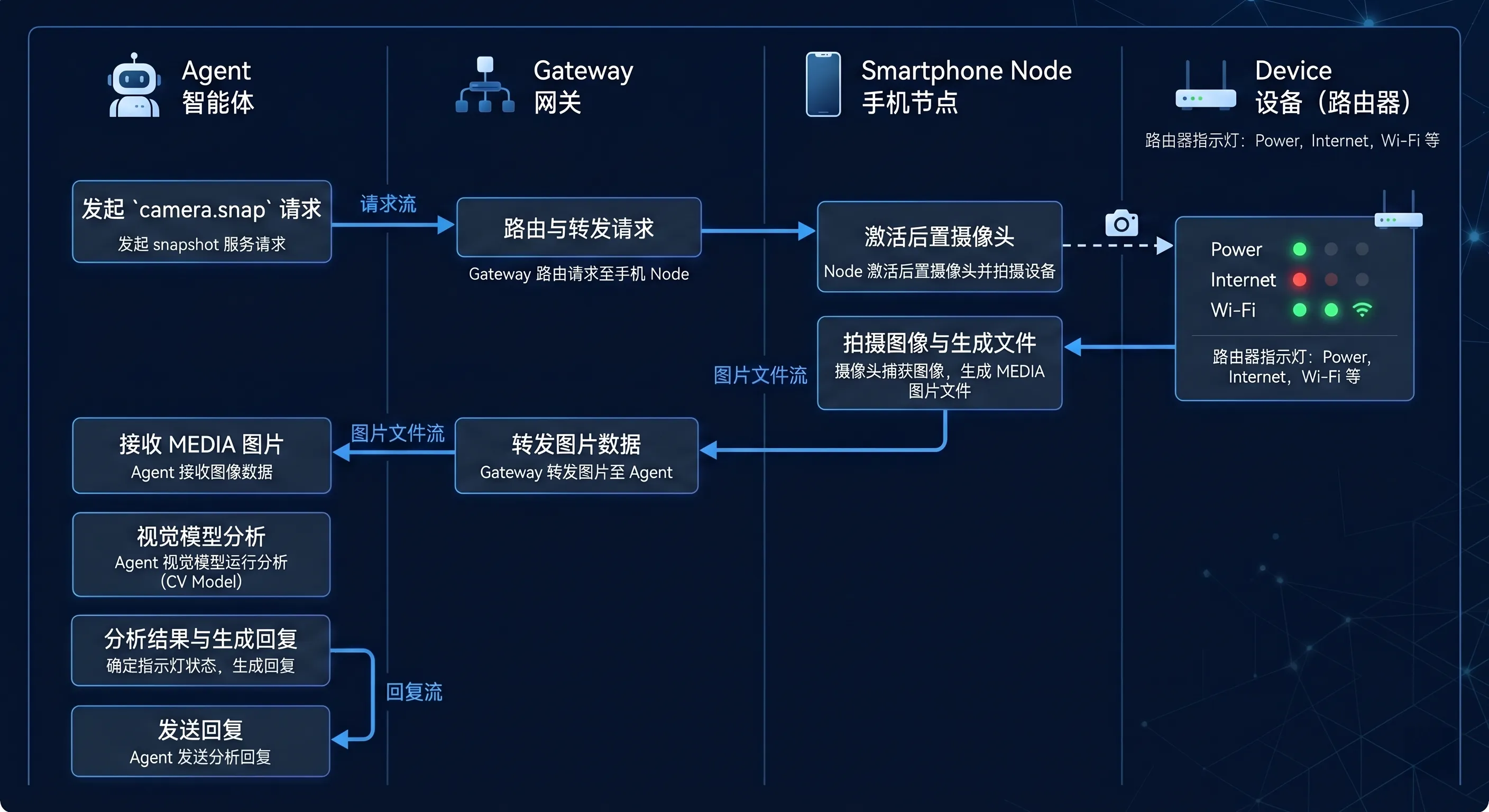
图:Agent 通过 Gateway 调用手机节点 camera.snap,节点拍照后返回媒体文件,Agent 可以进一步理解或转发。
五、短视频:适合观察动态变化
照片适合看静态状态。
短视频适合看动态过程。
比如:
- 设备指示灯是否闪烁
- 3D 打印机是否正常运动
- 门口是否有人经过
- 屏幕上的进度是否卡住
- 某个物理装置是否在工作
录制短视频
1 | openclaw nodes camera clip --node <idOrNameOrIp> --duration 10s |
或者:
1 | openclaw nodes camera clip --node <idOrNameOrIp> --duration-ms 3000 |
文档里说,camera clip 当前是 mp4,时长会被限制,最大大约 60 秒。
这不是限制你发挥,而是为了避免节点 payload 过大。
不录音
1 | openclaw nodes camera clip --node <idOrNameOrIp> --no-audio |
如果只是看画面,不需要声音,建议关掉音频。
原因很简单:
- 更少隐私风险
- 文件更小
- 权限更少
- 失败概率更低
什么时候用视频,什么时候用照片?
我建议这样判断:
| 场景 | 推荐 |
|---|---|
| 看设备灯亮不亮 | 照片 |
| 看灯是不是闪烁 | 短视频 |
| 看白板 / 文档 | 照片 |
| 看打印机是否在动 | 短视频 |
| 看屏幕报错 | 截图 / 照片 |
| 看一段操作过程 | 短视频 |
一句话:
能用照片解决,就不要先上视频。
六、macOS 摄像头:桌面环境里的视觉输入
macOS app 也可以作为 node,提供摄像头能力。
但有个重要区别:
macOS companion app 的 Allow Camera 默认是 off。
也就是说,你要在 macOS app 设置里允许 Camera。
文档里写的是:
1 | Settings → General → Allow Camera |
如果没开,camera 请求会返回类似:
1 | Camera disabled by user |
macOS 拍照示例
1 | openclaw nodes camera list --node <id> |
macOS 录短视频
1 | openclaw nodes camera clip --node <id> --duration 10s |
macOS 上还要注意系统权限:
- Camera
- Microphone
- Screen Recording
如果系统权限没给,OpenClaw 节点在线也没用。
七、屏幕录制:更适合验证桌面状态
摄像头看现实世界。
屏幕录制看桌面世界。
比如:
- 浏览器页面是否正常
- 某个 App 是否卡住
- 登录页面是否跳转
- 自动化流程是否真的执行
- 图表是否刷新
macOS screen video 可以这样用:
1 | openclaw nodes screen record --node <id> --duration 10s --fps 15 |
注意:
- 需要 macOS Screen Recording 权限
- iOS / Android 的 screen 相关能力通常也受系统限制
- 移动端 App 在后台可能返回
NODE_BACKGROUND_UNAVAILABLE
屏幕能力很强,但也很敏感。
建议:
只录必要时长,只录必要设备,不要长期开放屏幕采集。
八、移动端前台限制:不是 bug
第 23 课讲过一次,这里再强调。
iOS / Android 上这些能力常常要求 App 在前台:
camera.*canvas.*screen.*
如果 App 在后台,可能返回:
1 | NODE_BACKGROUND_UNAVAILABLE |
这不是配置错,也不是 Gateway 坏了。
这是移动系统对摄像头、屏幕、后台任务的限制。
所以手机媒体节点的正确使用方式是:
- 打开 OpenClaw App
- 保持前台
- 确认权限
- 再调用 camera / screen 能力
九、音频输入:语音消息怎么进入 Agent?
OpenClaw 的音频能力有两类。
第一类是用户发来的音频 / voice note。
比如你在 Telegram / WhatsApp 发一段语音。
OpenClaw 可以在 reply pipeline 前做 media understanding。
文档里的流程是:
- 找到第一个 audio attachment
- 必要时下载到本地
- 检查大小是否超过
maxBytes - 选择第一个可用 transcription model / CLI
- 转写成功后,把 Body 替换成
[Audio]block - 设置
{{Transcript}} - 命令解析使用 transcript
这意味着:
你发语音,Agent 可以先看到文字转写结果。
比如你发语音说:
1 | 帮我检查一下今天的 OpenClaw heartbeat 有没有异常 |
如果音频转写成功,Agent 会把它当成文字命令来理解。
![]()
图:用户发送语音消息后,OpenClaw 可以先转写音频,设置 Transcript,再让 Agent 使用文字内容进行回复。
十、音频理解默认怎么选择模型?
如果你没有特别配置 audio models,并且没有禁用 audio understanding,OpenClaw 会自动检测可用方案。
文档里的顺序大致是:
- 当前 active reply model,如果它支持 audio
- 本地 CLI,例如
sherpa-onnx-offline、whisper-cli、whisper - Gemini CLI
- Provider auth,例如 OpenAI、Groq、xAI、Deepgram、Google、SenseAudio、ElevenLabs、Mistral
你也可以显式配置。
示例:
1 | { |
这里的思路是:
先用 provider,失败时 fallback 到本地 CLI。
如果你不想处理音频,可以关闭:
1 | { |
十一、图片 / 视频理解:把附件变成上下文
Media understanding 不只处理音频。
也可以处理:
- image
- video
高层流程类似:
- 收集 inbound attachments
- 按 image / audio / video 选择附件
- 选择合适 provider 或 CLI
- 失败就 fallback
- 成功后生成
[Image]、[Audio]、[Video]block - 保留用户 caption
- 原始附件仍然保留给模型或工具
比如用户发来一张路由器照片,并配文:
1 | 这个灯正常吗? |
OpenClaw 可以先得到类似:
1 | [Image] |
这样 Agent 就能更好地理解用户问题。
默认限制
文档里提到常见默认上限:
- image:10MB
- audio:20MB
- video:50MB
超出时会跳过当前模型,尝试 fallback。
如果仍然处理不了,回复流程不会直接崩掉,而是继续带原始附件或上下文。
十二、媒体理解和节点采集怎么配合?
它们可以串起来。
比如你对 Agent 说:
1 | 用手机后置摄像头看一下路由器灯,然后告诉我网络是否正常。 |
理想流程:
- Agent 识别需要现场图片
- Gateway 调用手机 Node 的
camera.snap - 手机拍照并返回图片
- Agent 使用视觉模型分析图片
- Agent 回复判断结果
再比如:
1 | 录 10 秒看看 3D 打印机有没有在动。 |
流程:
- 调用
camera.clip - 返回 mp4
- 视频理解模型摘要运动状态
- Agent 回复是否异常
这里的关键是:
camera / screen 负责采集,media understanding / vision model 负责理解。
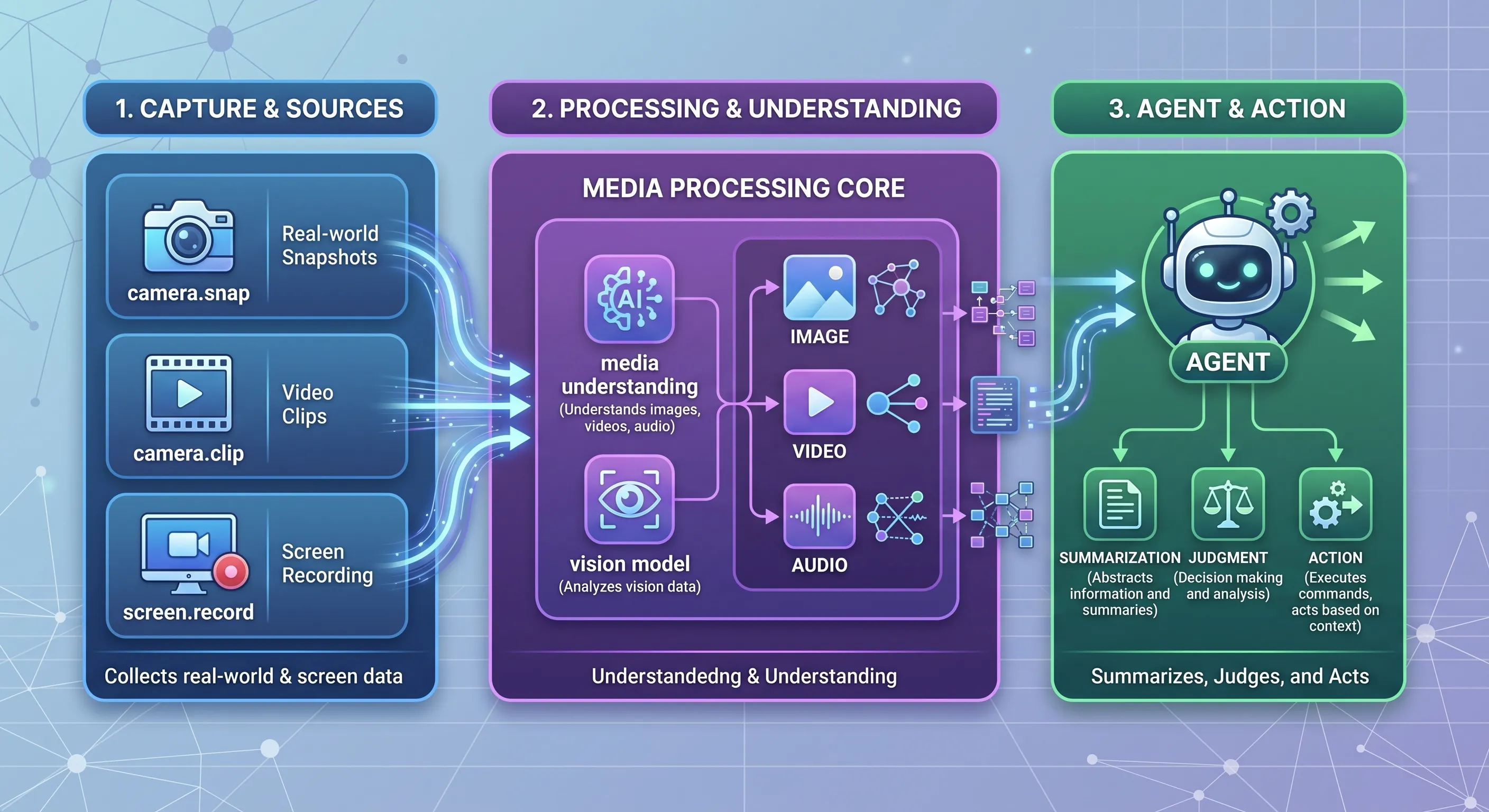
图:节点采集图片或视频后,Gateway 可以把媒体交给视觉模型或媒体理解流程,最终让 Agent 输出结论。
十三、媒体回复:把文件发回聊天
OpenClaw 也支持发送媒体。
CLI 形式:
1 | openclaw message send --media <path-or-url> --message "这是截图" |
媒体可以是:
- 本地文件 path
- HTTP(S) URL
WhatsApp Web 的媒体规则里,文档提到:
- 图片会 resize / recompress 到合理大小
- audio / voice / video 有大小限制
- documents 可以保留文件名
- caption 可以来自
--message - 多媒体回复会顺序发送
在文章里你不用死记每个上限。
只要知道:
媒体发送不是无限制的,图片、音频、视频、文档都有大小和格式边界。
如果发送失败,先看:
- 文件是否存在
- 文件是否太大
- MIME 是否能识别
- 渠道是否支持
- 日志里有没有 clear error
十四、TTS:让 OpenClaw 用声音回复
音频不只是输入,也可以是输出。
OpenClaw 的 TTS 可以把文字转成语音。
文档里说,TTS 支持多个 provider,并且在 Telegram / WhatsApp 等渠道可以用 voice note 或音频附件形式发送。
最简单的试用方式是:
1 | /tts audio 你好,这是 OpenClaw 的语音回复。 |
或者启用自动 TTS:
1 | { |
但我不建议新手一开始就开 always。
原因是:
- 每条回复都变语音,可能打扰人
- 会增加成本
- 群聊里尤其不适合
- 某些 provider 有额度限制
更好的方式是:
1 | 需要语音时明确要求 TTS |
比如:
1 | 请用语音总结这张图片里的内容。 |
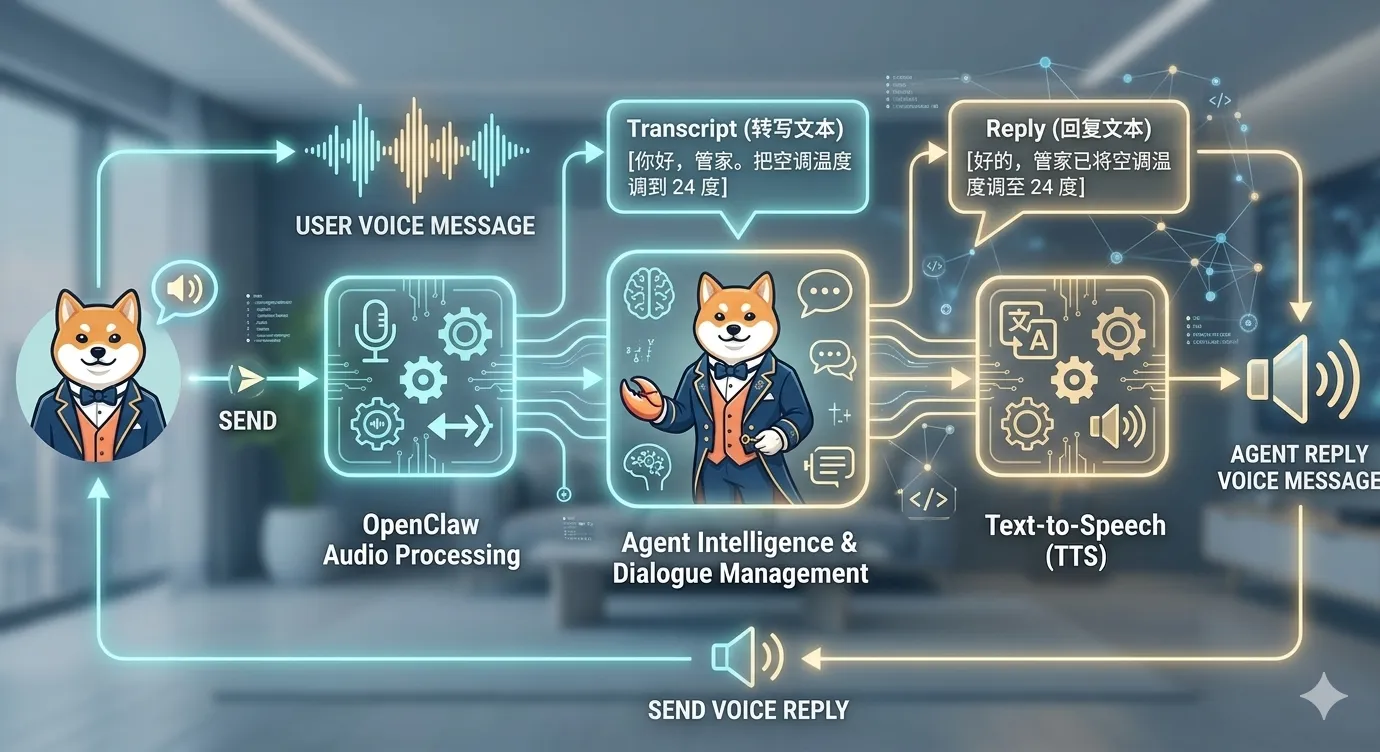
图:用户可以发送语音给 OpenClaw,OpenClaw 转写后理解,也可以通过 TTS 把回复变成语音发回用户。
十五、一个实战工作流:看设备指示灯
场景:你不在家,但想看路由器灯是否正常。
你可以对 OpenClaw 说:
1 | 用客厅手机节点后置摄像头拍一张路由器照片,帮我判断网络状态。 |
Agent 可能执行:
1 | openclaw nodes camera snap --node living-room-phone --facing back --max-width 1280 |
然后根据图片分析:
- 电源灯是否亮
- WAN 是否亮
- LAN 是否闪烁
- 是否有红灯
- 是否有异常文字或图标
最后回复:
1 | 我看到 Power 和 WAN 都亮着,LAN 在闪烁,没有明显红灯。初步看网络设备是在线的。如果你仍然不能上网,下一步建议从树莓派节点 ping 网关和公网 DNS。 |
这里最重要的是:
摄像头只解决“看见”,判断仍然要结合上下文。
十六、一个实战工作流:看 3D 打印机是否卡住
照片不一定够。
你可以让节点录短视频:
1 | 用打印机旁边的手机节点录 10 秒视频,帮我判断打印头有没有移动。 |
可能命令:
1 | openclaw nodes camera clip --node printer-phone --facing back --duration 10s --no-audio |
为什么加 --no-audio?
因为这个场景只需要画面。
少采集麦克风,就少一个隐私风险。
Agent 可以根据视频摘要判断:
- 打印头是否移动
- 灯光是否正常
- 打印件是否明显脱落
- 画面中是否有异常震动
十七、一个实战工作流:语音创建任务
你走在路上,不方便打字。
直接给 Telegram bot 发语音:
1 | 今晚八点提醒我检查 OpenClaw heartbeat 日志 |
OpenClaw 音频理解成功后,会把语音转成 transcript。
Agent 看到的是文字命令。
如果你前面学过 cron / heartbeat,就可以继续让它创建提醒或生成任务建议。
注意:
对重要操作,语音转写后最好让 Agent 复述确认。
因为语音识别可能听错。
比如:
1 | 我理解的是:今晚 20:00 提醒你检查 OpenClaw heartbeat 日志。是否确认? |
十八、一个实战工作流:收到图片后自动解释
你发一张报错截图给 bot,并配文:
1 | 这个报错是什么意思? |
如果 image understanding 可用,OpenClaw 会把图片摘要作为上下文。
Agent 可以:
- 读截图里的错误信息
- 解释原因
- 给出排查步骤
- 必要时让 browser / exec / file 工具继续查
这里的关键是:
图片不是单独存在的,caption 也很重要。
用户文字会作为 User text 保留。
十九、媒体能力的安全清单
媒体能力越强,越要克制。
我建议你给自己定几条规则。
1)摄像头默认不做长期自动采集
不要让 Agent 在没有明确请求时随便拍照。
2)短视频尽量短
优先 3 秒、5 秒、10 秒。
不要一上来 60 秒。
3)能不用麦克风就不用
比如看 3D 打印机、看路由器灯,通常不需要声音。
4)屏幕录制要特别谨慎
屏幕可能包含:
- 密码
- 私聊
- 邮箱
- API key
- 个人资料
5)群聊慎用语音和媒体自动理解
群聊里隐私边界更复杂。
建议用 scope rules 限制。
6)媒体文件可能很大
注意大小、时长和模型成本。
7)保存媒体要有边界
CLI helper 可能写临时文件。
不要把敏感照片长期留在公共目录。
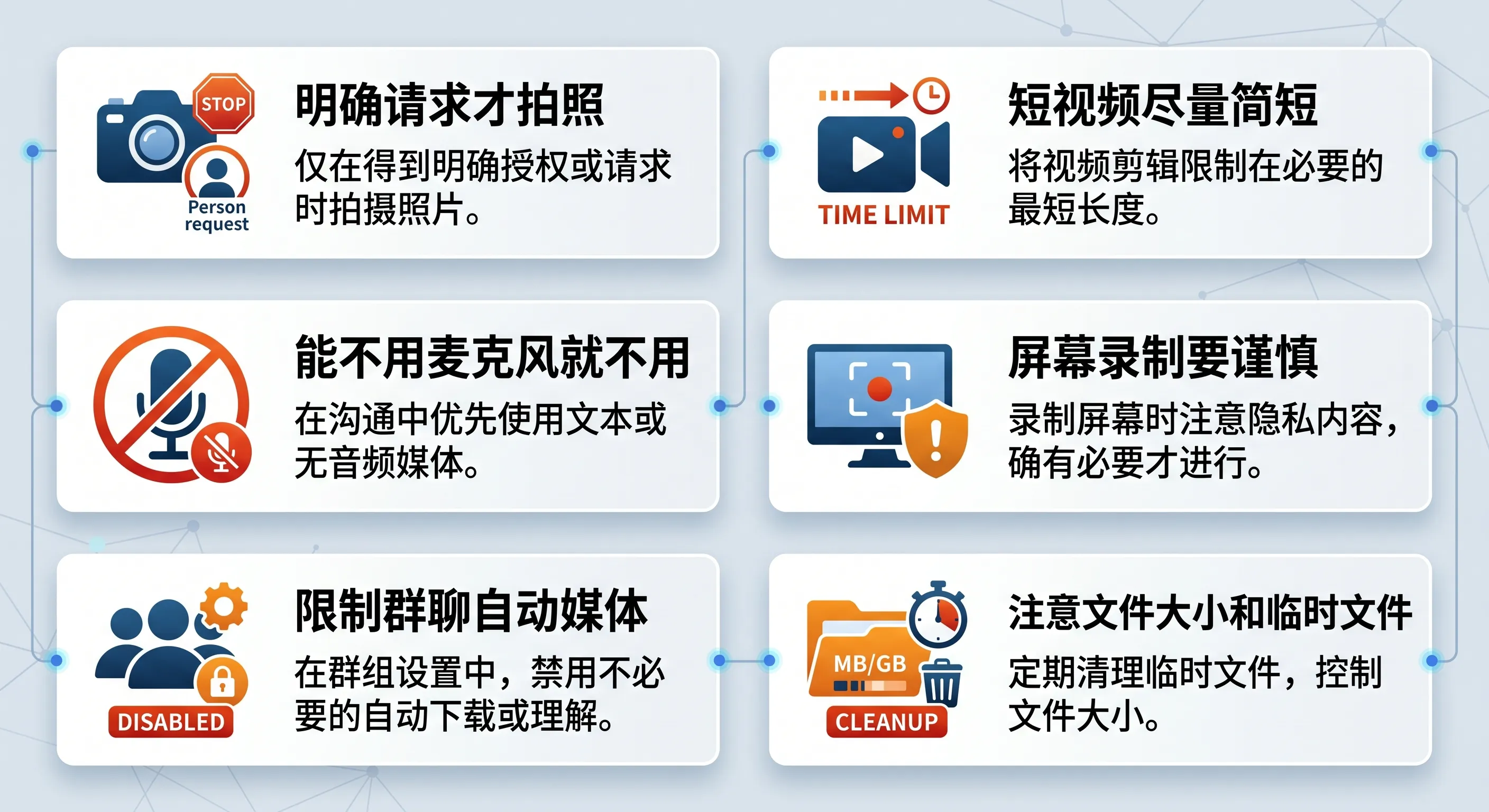
图:媒体节点能力很强,但要坚持最小采集、最小时长、最小权限和明确用户意图。
二十、常见错误和处理方向
1)CAMERA_DISABLED
原因:节点 App 里 camera 被关闭。
处理:打开节点设置里的 Allow Camera。
2)NODE_BACKGROUND_UNAVAILABLE
原因:移动端 App 在后台。
处理:把 OpenClaw App 切到前台。
3)*_PERMISSION_REQUIRED
原因:系统权限没给。
处理:到系统设置里允许 Camera / Microphone / Screen Recording / Location。
4)音频没有被转写
可能原因:
- audio understanding 被禁用
- 文件太大
- 音频太小或损坏
- provider 没有 auth
- 本地 CLI 不在 PATH
- 模型超时
5)视频理解失败
可能原因:
- 视频超过
maxBytes - provider 不支持 video
- CLI 配置错误
- 网络或 API 失败
6)媒体发送失败
可能原因:
- 文件路径不存在
- 文件太大
- 渠道不支持该类型
- MIME 识别失败
- 远程 URL 下载失败
二十一、适合新手的提问模板
下面这些可以直接复制。
1)检查媒体节点能力
1 | 请帮我检查当前 OpenClaw 节点是否支持 camera、screen、audio/media 相关能力。只做只读检查,先看 nodes status 和 nodes describe。 |
2)用手机节点拍照
1 | 请用手机节点后置摄像头拍一张照片,限制最大宽度 1280,然后帮我描述图中内容。只拍一次,不要录像。 |
3)录短视频但不录音
1 | 请用打印机旁边的节点录制 10 秒短视频判断设备是否在动,不要录音,完成后总结观察结果。 |
4)排查 camera 失败
1 | camera.snap 失败了。请按 CAMERA_DISABLED、NODE_BACKGROUND_UNAVAILABLE、系统 Camera 权限、Gateway command policy、nodes describe 这几个方向排查。 |
5)排查语音转写
1 | 我发的语音没有被 OpenClaw 转写。请检查 tools.media.audio 是否启用、provider/CLI 是否可用、文件大小是否超过限制、日志里是否有转写错误。 |
6)谨慎使用屏幕录制
1 | 请先说明屏幕录制可能暴露哪些隐私,再只录制 5 秒目标节点屏幕,不要持续录制。 |
7)TTS 语音回复
1 | 请把刚才的结论用一段简短语音发给我,文字不要太长,适合语音听。 |
二十二、这一课最值得记住的一句话
如果今天只记一句话:
Camera / screen 负责采集现实和桌面,media understanding 负责理解附件,TTS 负责把回复变成声音。
再记一句安全原则:
媒体能力越接近现实世界,越要最小权限、最小时长、明确触发。
二十三、总结
今天这节课,我们把 OpenClaw 的媒体节点能力串起来了:
- 节点媒体能力可以让 Agent 看见现实世界和桌面状态。
camera.snap适合静态观察,camera.clip适合动态观察。- 能用照片解决,就不要先用视频。
- 能不用麦克风,就加
--no-audio。 - macOS 摄像头默认需要手动开启 Allow Camera。
- 屏幕录制需要系统权限,且隐私风险更高。
- 移动端 camera / screen / canvas 常常要求 App 在前台。
- 用户发来的语音可以通过 audio understanding 转成 Transcript。
- 图片 / 视频可以通过 media understanding 变成 Agent 上下文。
- 媒体回复可以通过 message send 或 Agent 回复携带。
- TTS 可以让 OpenClaw 用声音回复,但不建议新手默认 always。
- 媒体能力强大,但必须坚持最小权限和明确意图。
至此,第五模块「多平台与节点」就完整了:
- 第 21 课:多节点架构
- 第 22 课:Tailscale 组网
- 第 23 课:节点配对排错
- 第 24 课:摄像头 / 音频 / 媒体节点实战
你现在已经有了一个完整的多设备 OpenClaw 心智模型。
下一模块,我们进入安全与运维。
下一课预告
下一课我们会讲:
第 25 课:权限控制——elevated / sandbox / tool policy
会重点讲:
- elevated 到底是什么
- sandbox 和 tool policy 的区别
- 为什么 exec 不应该随便 full
- allowlist / ask / deny 怎么选
- 多节点下权限控制为什么更重要
- 怎么设计一个安全但不难用的 OpenClaw 权限模型
🦞 本文由八条撰写,持续更新中。